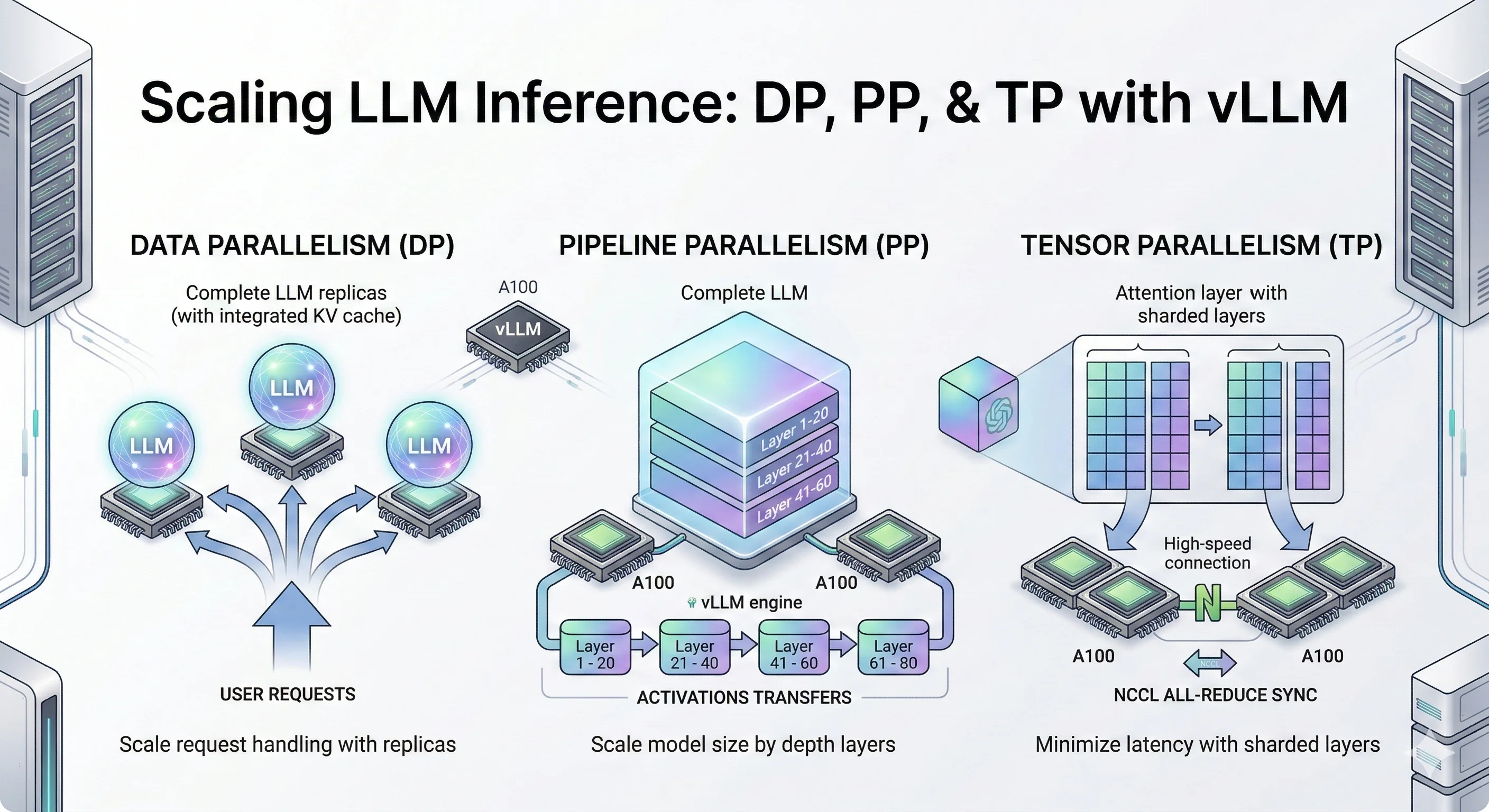
Benchmarking Gemma 4 MTP vs DFlash on a Single H100

Speculative decoding speeds up LLM serving by using a smaller draft model to propose several tokens at once. The larger target model then verifies those tokens in parallel, so a single verification step can produce multiple accepted tokens instead of just one.
The speedup depends on the model, workload, and serving setup. Even with the right draft model, the gains can look different across dense and MoE models, across prompt categories, and across concurrency levels.
We wanted a simple answer for Gemma 4 on a single H100: how much faster do MTP and DFlash make serving, and does one method clearly win?
There was no single winner. On Gemma 4 31B dense, MTP was ahead. On Gemma 4 26B-A4B MoE, DFlash was ahead. Both speculative decoding techniques were much faster than baseline, but the winner changed with the model and workload.
Google has already explained Gemma 4 MTP. We wanted to test the serving side: on one H100, how much speed do we actually get, and does MTP or DFlash look better?
Quick Background: MTP and DFlash
Gemma 4 MTP uses Google's paired assistant checkpoints for Gemma 4. The assistant is a small draft model that shares target-model state, including the input embeddings and last-layer activations, so it can propose useful draft tokens cheaply. The full Gemma 4 model then verifies those tokens in one target-model pass.
DFlash changes the draft model itself. A normal autoregressive draft model still proposes draft tokens one after another, so drafting cost grows as k gets larger. DFlash uses a lightweight block-diffusion draft model that proposes the whole block in a parallel forward pass, making draft cost much flatter as k increases. The target model still verifies the proposed block, but DFlash is trying to make the draft side much cheaper.
What We Tested
We used the SPEED-Bench qualitative dataset because speculative decoding is very workload-sensitive. A coding prompt, a math prompt, and a writing prompt do not behave the same way. Coding and reasoning tasks often have more predictable next-token structure, so the draft model can sometimes get longer accepted spans. Open-ended writing or roleplay can be harder because there are many reasonable ways to continue the text, which usually makes the gains smaller.
SPEED-Bench is NVIDIA's newer benchmark for speculative decoding. The dataset card frames it as an improvement over earlier benchmarks like SpecBench: it is meant to standardize speculative-decoding evaluation across semantic domains and realistic serving regimes, while measuring both acceptance behavior and end-to-end throughput.
We used its qualitative split, which has 880 prompts across 11 categories: coding, humanities, math, multilingual, QA, RAG, reasoning, roleplay, STEM, summarization, and writing. Each category has 80 prompts chosen for semantic diversity. That matters for this benchmark because a single average can hide the real behavior. We wanted to see which categories benefit the most, which benefit less, and whether MTP and DFlash behave differently across workloads.
We ran everything on one JarvisLabs H100 80GB with vLLM. The sweep used concurrency levels 1, 2, 4, 8, and 16, with an output cap of 4096 tokens. Temperature was set to 0 so the models followed the same greedy decoding path every time. Prefix caching was disabled so cached prompts would not skew the throughput numbers.
The shared benchmark settings were:
| Setting | Value |
|---|---|
| Hardware | 1x H100 80GB |
| Serving runtime | vLLM |
| Dataset | SPEED-Bench qualitative |
| Categories | 11 categories, 80 prompts each |
| Concurrency sweep | 1, 2, 4, 8, 16 |
| Max model length | 32768 |
| Max output tokens | 4096 |
| Server scheduler token cap | --max-num-batched-tokens 4096 |
| Sampling | temperature=0 |
| Prefix caching | disabled |
| Gemma serving mode | --language-model-only |
Reproduce the run: The exact serving commands and benchmark scripts are in the companion repo: Gemma 4 MTP vs DFlash Benchmark. You can use them to reproduce the numbers from this post on the same setup.
The target models were google/gemma-4-31B-it and google/gemma-4-26B-A4B-it. For each target model, we compared three serving modes:
- Baseline decoding with no draft model.
- MTP speculative decoding.
- DFlash speculative decoding.
For MTP, we used Google’s matching assistant draft models: google/gemma-4-31B-it-assistant for the dense model and google/gemma-4-26B-A4B-it-assistant for the MoE model. The main MTP comparison used k=8, where k is the number of speculative tokens proposed per draft cycle.
For DFlash, we used the matching z-lab draft models: z-lab/gemma-4-31B-it-DFlash and z-lab/gemma-4-26B-A4B-it-DFlash. DFlash used k=15, matching the z-lab Gemma 4 vLLM command. The serving setup used triton_attn for the target model and flash_attn for the DFlash draft model. For Gemma 4 DFlash, we followed the official z-lab DFlash repository instructions and built vLLM from vLLM PR #41703:
uv pip install -U --torch-backend=auto \
"vllm @ git+https://github.com/vllm-project/vllm.git@refs/pull/41703/head"Here is the headline throughput at concurrency 1.
| Model | Baseline c1 | MTP c1 | DFlash c1 | Winner in this run |
|---|---|---|---|---|
| Gemma 4 31B dense | 40.3 tok/s | 125.3 tok/s | 122.1 tok/s | MTP |
| Gemma 4 26B-A4B MoE | 177.1 tok/s | 264.2 tok/s | 306.4 tok/s | DFlash |
On the dense 31B model, MTP and DFlash were very close at low concurrency, with MTP slightly ahead. On the 26B-A4B MoE model, DFlash had a clearer lead. The full figures below show the same comparison across the concurrency sweep and by category.
Gemma 4 31B Dense
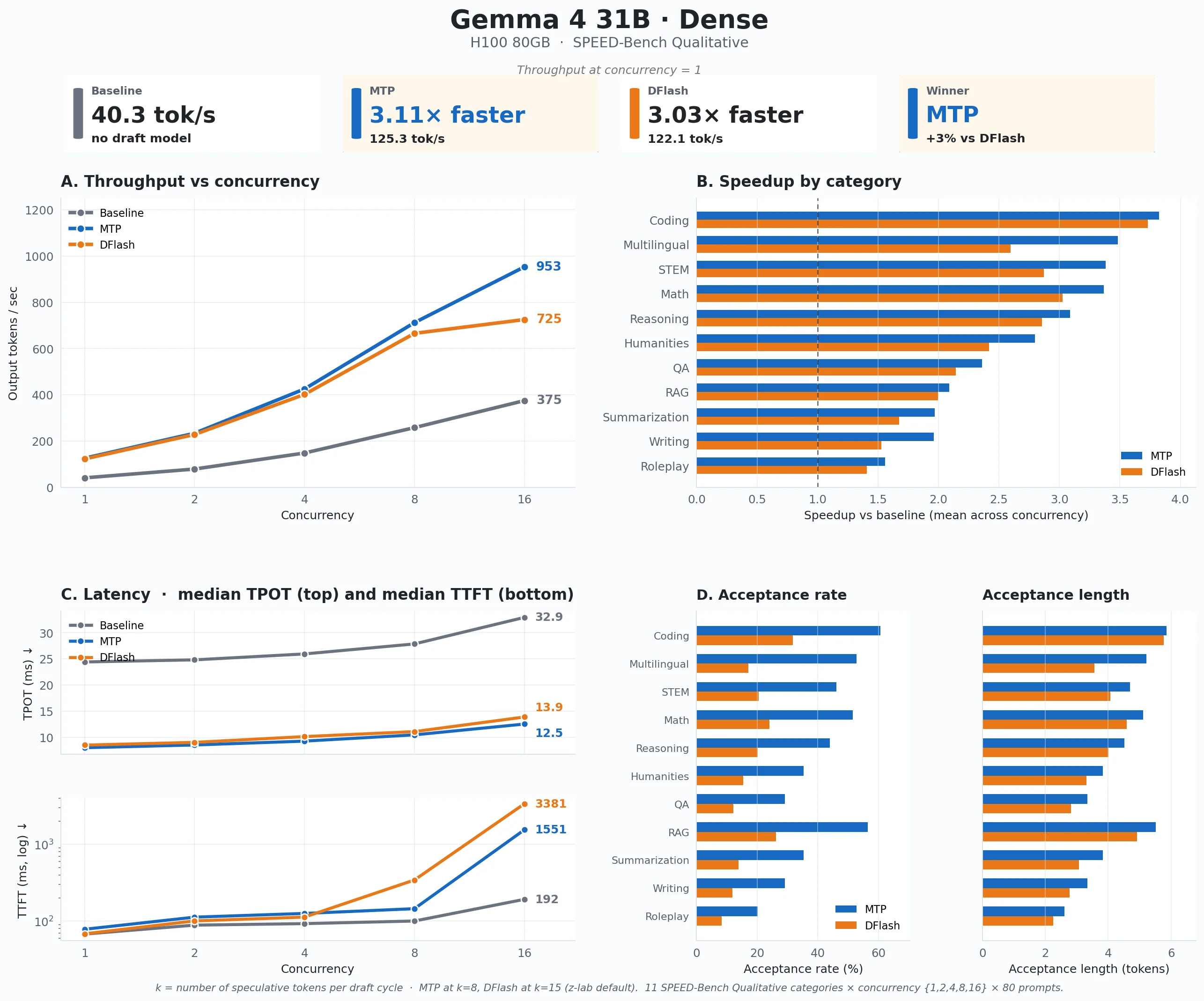
On Gemma 4 31B dense, MTP had the edge. At concurrency 1, baseline decoding produced 40.3 output tokens per second. MTP reached 125.3 output tokens per second, or 3.11x faster than baseline. DFlash was close at 122.1 output tokens per second, or 3.03x faster than baseline.
The category and latency plots explain where that speedup came from:
- MTP scaled better at higher concurrency. At concurrency 16, baseline reached 375 output tokens per second, DFlash reached 725 output tokens per second, and MTP reached 953 output tokens per second. So the low-concurrency result was close, but MTP opened a larger gap as more requests were in flight.
- Coding was the strongest category. Across the concurrency sweep, coding averaged 3.82x speedup with MTP and 3.73x with DFlash. Math and reasoning also did well: MTP reached 3.37x on math and 3.09x on reasoning, while DFlash reached 3.02x and 2.86x.
- Open-ended categories gained less. Writing averaged 1.96x with MTP and 1.53x with DFlash. Summarization was similar at 1.97x and 1.68x. Roleplay was the weakest category, at 1.56x for MTP and 1.41x for DFlash.
- This pattern makes sense. Coding, math, and reasoning usually contain more predictable token sequences: syntax, equations, numbered steps, repeated variable names, and common reasoning phrases. The draft model has an easier time guessing what comes next, so it can propose longer chunks before the target model rejects one. Writing and roleplay are open-ended. There are many reasonable ways to continue a sentence, so the draft model loses alignment faster.
- TPOT improved because one target-model step can produce multiple accepted tokens. TPOT means time per output token. Without speculative decoding, the target model decodes one token at a time. With speculative decoding, the draft model proposes a small block of tokens, and the target model verifies that block together. If several proposed tokens are accepted, one target-model verification step gives us several output tokens instead of one. That is why median TPOT on 31B dense dropped from 24.4 ms at baseline to 8.0 ms with MTP and 8.5 ms with DFlash at concurrency 1. At concurrency 16, baseline was 32.9 ms, MTP was 12.5 ms, and DFlash was 13.9 ms.
- TTFT got worse at high concurrency because speculative decoding adds work before the first token. TTFT means time to first token. Baseline needs prefill plus the first decode step. Speculative decoding also has to run the draft model, verify the proposed tokens, and decide which tokens were accepted before anything is returned. At low concurrency, that extra work was small: 67.7 ms baseline, 78.2 ms MTP, and 68.2 ms DFlash. At concurrency 16, it became visible: 192 ms baseline, 1551 ms MTP, and 3381 ms DFlash.
- That is the real trade-off. Speculative decoding gives you more tokens per second once generation starts (better TPOT), but under load the first token can take longer to arrive (worse TTFT). For batch jobs, that may not matter. For interactive products where users are waiting for the first word to appear, it does.
Gemma 4 26B-A4B MoE
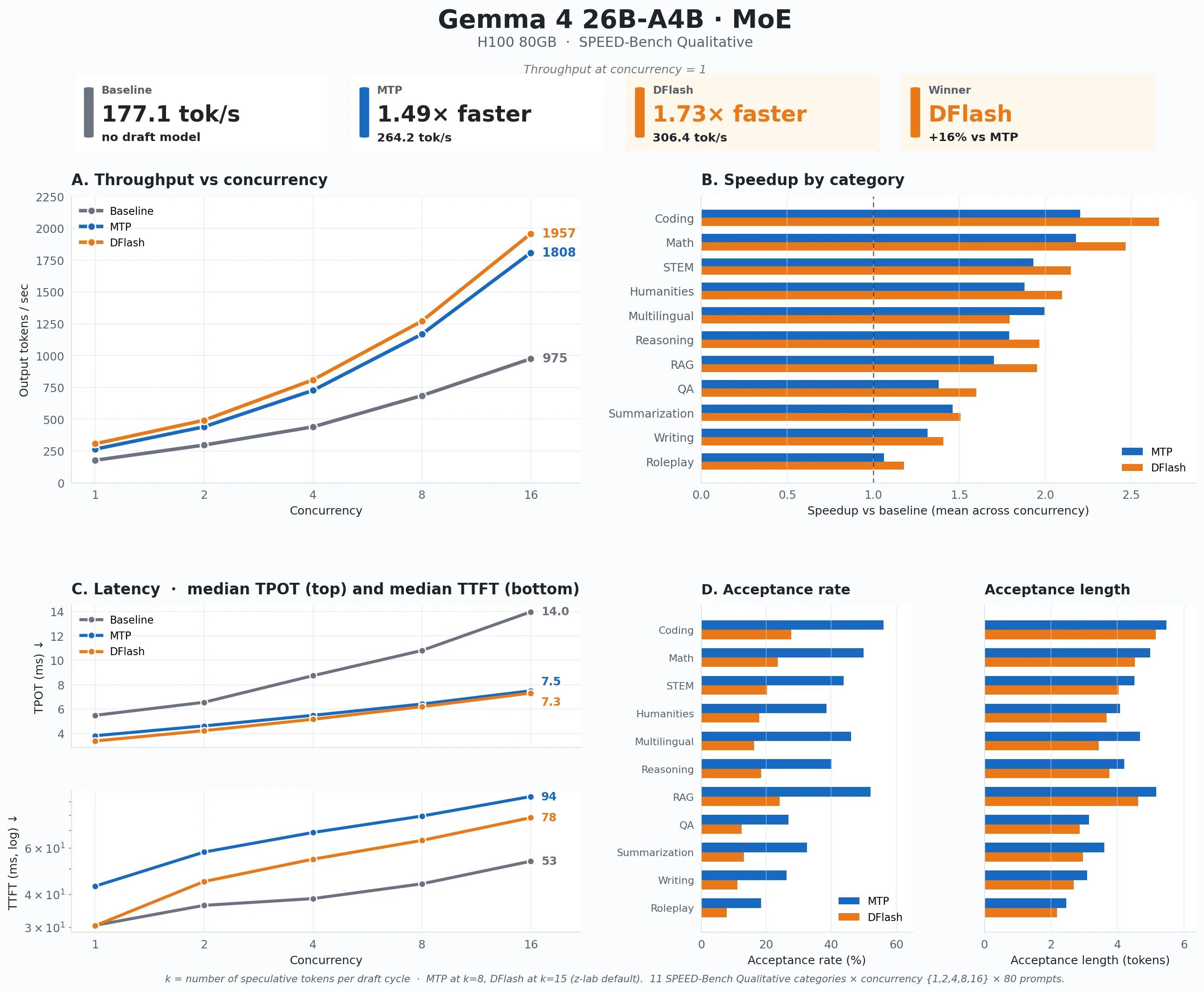
The 26B-A4B MoE model started from a much faster baseline. Even without speculative decoding, it produced 177.1 output tokens per second at concurrency 1, compared with 40.3 output tokens per second for the dense 31B model. That is expected: Gemma 4 26B-A4B has 25.2B total parameters, but only 3.8B active parameters during inference. It has the capacity of a larger MoE model, but the per-token compute cost is much closer to a small active model.
Speculative decoding still helped, but the speedup was smaller than on the dense model. That also makes sense: the MoE target model is already much cheaper to decode, so there is less target-model cost for speculative decoding to save. At concurrency 1, MTP reached 264.2 output tokens per second, or 1.49x faster than baseline. DFlash reached 306.4 output tokens per second, or 1.73x faster than baseline.
The rest of the MoE result is simpler:
- DFlash stayed ahead as concurrency increased. At concurrency 16, baseline reached 975 output tokens per second, MTP reached 1808 output tokens per second, and DFlash reached 1957 output tokens per second.
- DFlash won most categories. Across the concurrency sweep, DFlash led in 10 of 11 categories. The strongest gains were in coding (2.66x), math (2.47x), STEM (2.15x), humanities (2.10x), reasoning (1.97x), and RAG (1.95x) versus baseline.
- Multilingual was the exception. MTP averaged 1.99x on multilingual, while DFlash averaged 1.79x. That was the only category where MTP stayed ahead on the MoE model.
- The TTFT trade-off was much smaller than on dense 31B. On the dense model at concurrency 16, speculative decoding pushed TTFT from 192 ms baseline to 1551 ms with MTP and 3381 ms with DFlash. On 26B-A4B, baseline TTFT was 53.5 ms, MTP was 94.1 ms, and DFlash was 78.2 ms. That is less of a trade-off. The reason is the same reason the baseline is fast: each MoE forward pass only activates 3.8B parameters, so the extra draft and verification work does not pile up as badly under load.
Acceptance by Draft Position
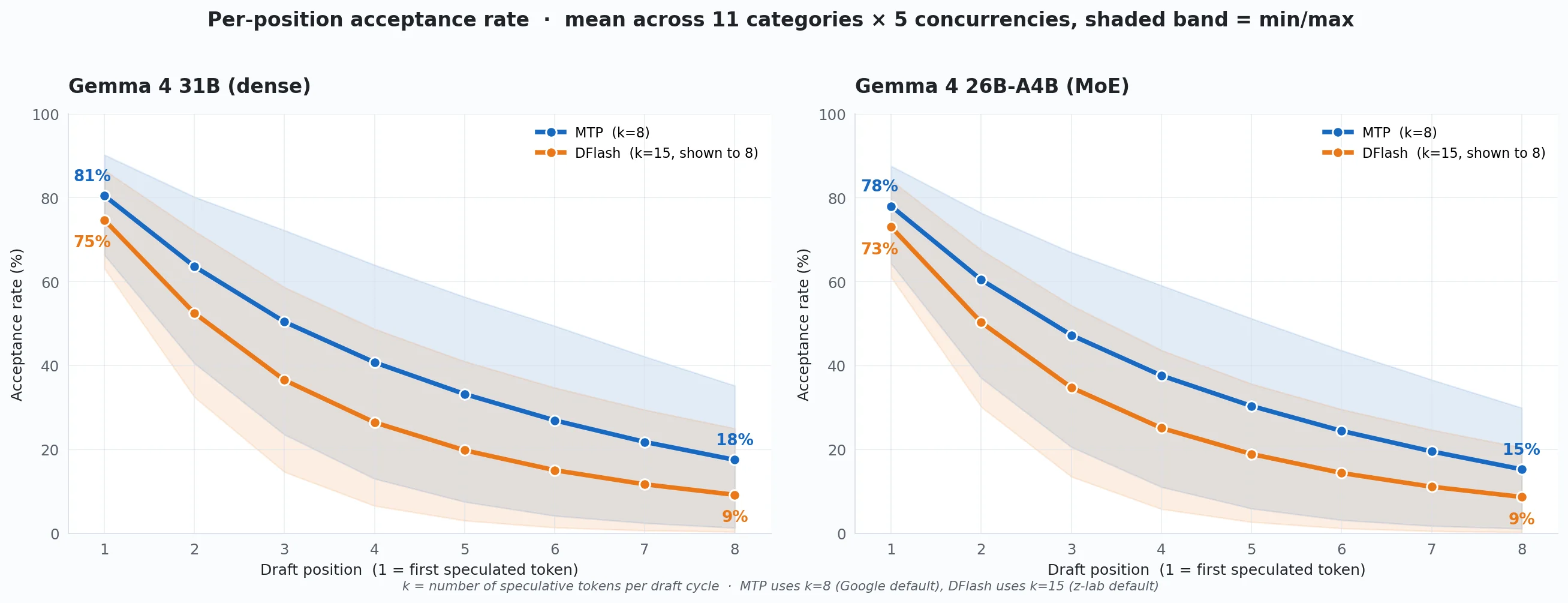
This chart shows how acceptance falls as the draft model looks further ahead, averaged across all 11 categories and all five concurrency levels. MTP uses k=8 and DFlash uses k=15; we show the first eight DFlash positions so the curves line up.
Two things stand out. First, most of the useful work happens early. Acceptance drops quickly for both methods on both models, so the throughput win mostly comes from the first few draft tokens that survive verification. The later positions contribute much less.
Second, MTP has higher per-position acceptance than DFlash on both models among the first eight positions shown. On dense 31B, that matches the throughput result: MTP accepts more draft tokens and wins. On 26B-A4B MoE, it is more interesting. DFlash wins throughput even with lower per-position acceptance, which means acceptance is not the whole story. Because the MoE target only activates 3.8B parameters, each target forward pass is already cheap, so draft cost, attention backend, and verification overhead matter more.
Conclusion
On this single-H100 setup, MTP was the better starting point for Gemma 4 31B dense, while DFlash was the better starting point for Gemma 4 26B-A4B MoE.
The main lesson is that speculative decoding works best when you match it to the setup. The result depends on the model, the workload, the hardware, and whether you care more about throughput or first-token latency.
For a production setup, it is worth spending the time to benchmark MTP, DFlash, and other available speculative decoding techniques on your own prompts and setup. A few hours of measurement can save much more GPU time and cost later.
If you want to know more about speculative decoding and the available methods in vLLM, read our Speculative Decoding in vLLM guide. It walks through how draft-and-verify works in vLLM, how methods like draft models, n-gram, suffix decoding, MLP speculators, and EAGLE differ, and what to watch when you benchmark them.
Get Started
Build & Deploy Your AI in Minutes
Cloud GPU infrastructure designed specifically for AI development. Start training and deploying models today.
View Pricing