What NVFP4 Gets You on the RTX PRO 6000 Blackwell
If you're serving a 30B-class model on a single GPU, the new RTX PRO 6000 Blackwell with NVFP4 is worth a serious look. We benchmarked Qwen3-32B on vLLM across BF16, FP8, and NVFP4, and NVFP4 came out at roughly 2x BF16 throughput with no measurable accuracy loss on GPQA Diamond or ARC Challenge, and the lowest first-token latency at every concurrency point tested.
What that buys you depends on the workload. For chat or agentic products, the lower TTFT is what end users notice directly. A Qwen3-32B that starts responding in around 150 ms instead of 340 ms feels like a different product. For batch jobs like document summarization, evaluation pipelines, or large-scale classification, the throughput gain matters more: roughly twice the tokens per second per GPU means half the GPUs, or half the wall-clock time, for the same workload. And for agentic stacks that chain many model calls in sequence, both effects compound at every step.
In this writeup we walk through the precision formats themselves, the full ShareGPT serving sweep, the GPQA Diamond and ARC Challenge accuracy numbers, and the points where the NVFP4 speedup tightens at high concurrency. The RTX PRO 6000 Blackwell Server Edition used in this benchmark is now part of Jarvislabs' GPU inventory.
NVIDIA's RTX PRO 6000 Blackwell Server Edition has the largest memory of any GPU in their professional PCIe lineup: 96 GB of GDDR7 at roughly 1.6 TB/s, 24,064 CUDA cores, 752 fifth-generation Tensor Cores, and a configurable 600 W TDP in a passively-cooled, dual-slot server card. It's NVIDIA's inference-side Blackwell release, one architecture generation ahead of Hopper (H100, H200) and two ahead of Ada Lovelace (L40S).
The bigger inference change in Blackwell is in the 5th-generation Tensor Core, which is the first to support FP4 and FP6 natively. NVIDIA quotes up to 4 PFLOPS of FP4 on this card, with 2 PFLOPS of FP8 and 1 PFLOP of BF16/FP16. That hardware support is what turns NVFP4 (the 4-bit format used later in this post) into a real matmul speedup rather than a memory trick. Without native FP4 support, FP4-style checkpoints typically have to be dequantized to a wider type before the multiply runs, so the main win is memory footprint rather than tensor-core throughput.
For LLM serving, the practical effect of 96 GB plus hardware FP4 is that a wider range of models fits on a single card. A 70B model at FP8 or a 32B model at BF16 can fit on one device, though the KV cache budget depends on context length and batching settings. For workloads that do fit, you avoid the tensor-parallelism overhead that comes with splitting across multiple GPUs. The catch is memory bandwidth: 1.6 TB/s of GDDR7 is roughly a third of an H200's 4.8 TB/s HBM3e. For mid-size LLMs where the model and KV cache fit in 96 GB, capacity and FP4 throughput matter more in practice than peak bandwidth.
ShareGPT is used to measure serving behavior — throughput, TTFT, TPOT, and ITL across different concurrency levels. GPQA Diamond and ARC Challenge are then run through EleutherAI LM Evaluation Harness to check whether the lower-precision variants change benchmark accuracy.
The benchmark uses Qwen3-32B variants served with vLLM on the same RTX PRO 6000 system, so the comparison focuses on how precision changes latency, throughput, and benchmark accuracy. Before jumping into the experiments, a quick tour of the LLM precision formats involved.
LLM Precision Formats
LLM inference is often bottlenecked by memory movement, KV-cache traffic, and matrix multiplication throughput. The exact bottleneck depends on the phase — prefill tends to be compute-heavy, while decode is usually bandwidth- and KV-cache-bound — and it shifts further with batch size and concurrency. Either way, every token requires moving model weights, KV-cache data, and activations through the GPU. Precision formats decide how many bits are used to represent those numbers. Fewer bits usually means less memory traffic, better cache behavior, and higher throughput, but it can also reduce numerical detail.
A floating-point number is usually split into three fields: sign, exponent, and mantissa. The sign bit stores positive or negative. The exponent controls the range of values that can be represented. The mantissa, also called the significand, controls precision inside that range. In LLM serving, the key tradeoff is range versus precision versus bandwidth.
BF16
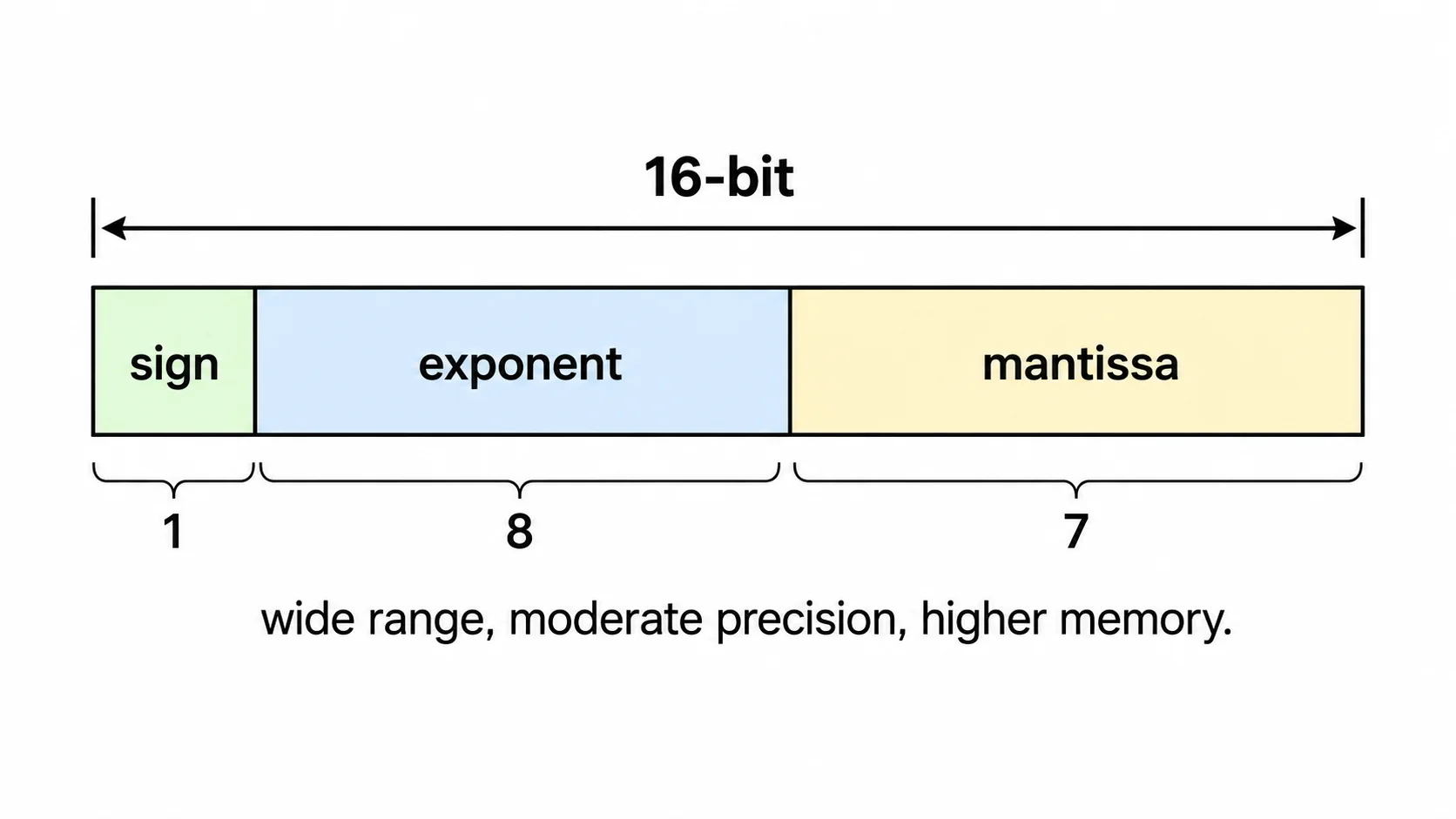
BF16 means bfloat16. It is a 16-bit floating-point format with 1 sign bit, 8 exponent bits, and 7 mantissa bits.
| Field | Bits | Purpose |
|---|---|---|
| Sign | 1 | Stores positive or negative |
| Exponent | 8 | Gives BF16 a wide dynamic range |
| Mantissa | 7 | Stores precision bits |
| Total | 16 |
BF16 works well as a baseline because it keeps the same exponent width as FP32. That means it can represent very small and very large values without underflowing or overflowing as easily as narrower formats. The tradeoff is more memory per value than FP8 or NVFP4, so serving can become bandwidth-limited sooner.
BF16 serves as the baseline in this post since it is the safest starting point to verify the model and serving stack work correctly.
FP8
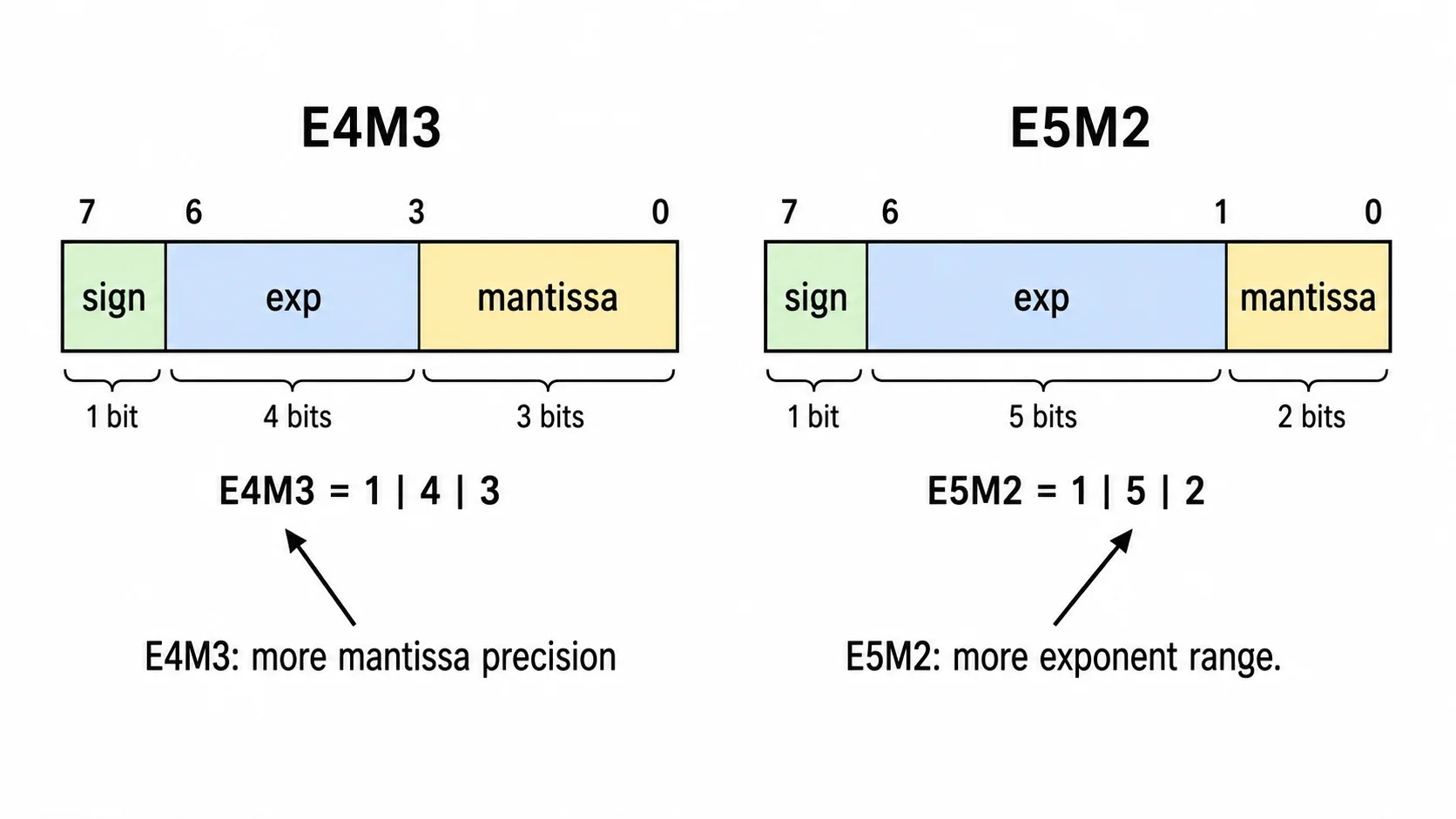
FP8 is an 8-bit floating-point family. Common FP8 variants include E4M3 and E5M2. E4M3 uses 1 sign bit, 4 exponent bits, and 3 mantissa bits. E5M2 uses 1 sign bit, 5 exponent bits, and 2 mantissa bits.
| Format | Sign bits | Exponent bits | Mantissa bits | Total bits | Main tradeoff |
|---|---|---|---|---|---|
| FP8 E4M3 | 1 | 4 | 3 | 8 | More precision, less range |
| FP8 E5M2 | 1 | 5 | 2 | 8 | More range, less precision |
Compared with BF16, FP8 cuts storage per value from 16 bits to 8 bits. That can reduce memory traffic and improve serving throughput, especially on newer GPUs with optimized FP8 tensor cores. The lower bit width means less precision, so FP8 models usually need quantization-aware calibration or a model checkpoint already prepared for FP8.
In these runs, FP8 lands between BF16 and NVFP4 on serving throughput. The accuracy differences on GPQA Diamond and ARC Challenge are small and metric-dependent (covered later), so we treat FP8 as a clear throughput win rather than a clean middle ground on quality.
NVFP4
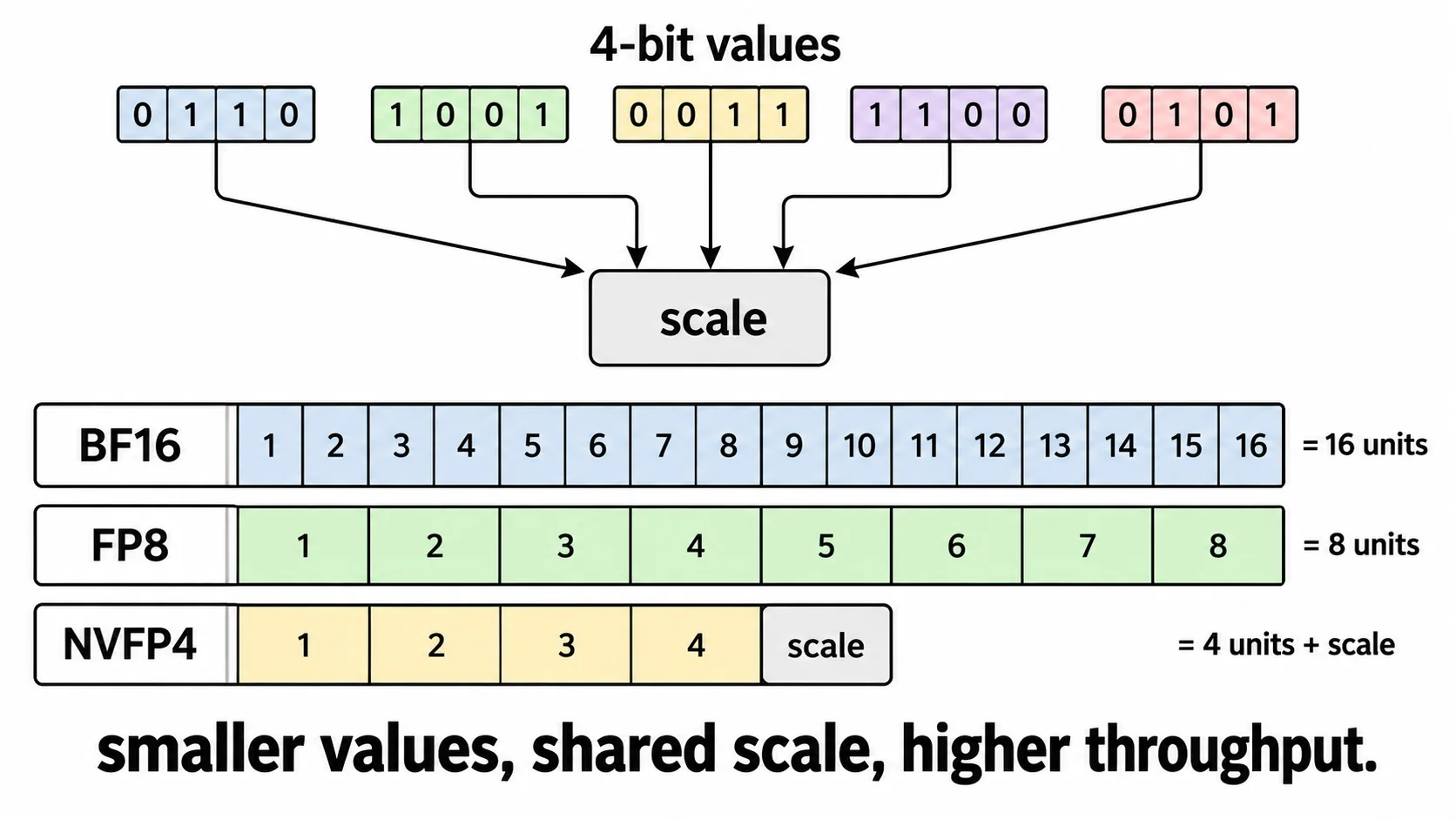
NVFP4 is NVIDIA's 4-bit floating-point format for low-precision inference. Each value is stored as FP4 E2M1 — 1 sign bit, 2 exponent bits, 1 mantissa bit. A 4-bit value cannot carry much by itself, so NVFP4 layers two levels of scaling on top: an FP8 E4M3 scale shared across each 16-value micro-block, plus a per-tensor FP32 scale. That two-level scheme is what lets the 4-bit payload cover a useful range.
At a high level, NVFP4 uses far fewer bits per weight than BF16 or FP8. The bits-per-value below is a derived figure (16 × 4-bit values + one 8-bit microblock scale = 72 bits per 16 values), before the per-tensor scale and any unquantized tensors:
| Format | Approx bits per value | Relative storage vs BF16 |
|---|---|---|
| BF16 | 16 | 1.00x |
| FP8 | 8 | 0.50x |
| NVFP4 | ~4.5 (incl. microblock scale) | ~0.28x before tensor scale |
Note also that not every tensor is quantized: per the RedHatAI/Qwen3-32B-NVFP4 model card, only the weights and activations of the linear operators inside transformer blocks are converted to FP4. The rest of the model stays in its original precision.
NVFP4 is more aggressive than FP8. It reduces memory movement further and can increase token throughput, but the model depends more heavily on good quantization and scaling. The main risk is accuracy loss, especially on tasks sensitive to small probability differences.
In these experiments, NVFP4 gave the best ShareGPT serving performance. It also did not show a measurable regression on GPQA Diamond or ARC Challenge in this single-run evaluation — faster serving without a noticeable accuracy drop on these two benchmarks.
Setup
| Item | Value |
|---|---|
| GPU | NVIDIA RTX PRO 6000 Blackwell Server Edition |
| Serving framework | vLLM |
For the latency test, ShareGPT is used to monitor TTFT, ITL, TPOT, and throughput across concurrency levels 8, 16, 32, 64, 128, and no-limit. For accuracy, two benchmarks are run through LM Evaluation Harness:
- GPQA Diamond — the hardest ~198-question subset of GPQA, a graduate-level multiple-choice science QA benchmark (biology, physics, chemistry).
- ARC Challenge — the 2,590-question "Challenge" split of AI2's ARC, containing grade-school science questions that simple retrieval/co-occurrence methods get wrong.
Both benchmarks are run against the served model via the local-completions adapter against vLLM's /v1/completions endpoint. That means no chat template is applied and Qwen3's thinking mode is not engaged, so these scores are not directly comparable to the chat-style numbers on the Qwen model card — they are useful as an apples-to-apples precision comparison on this serving stack, not as absolute Qwen3-32B quality measurements.
| Precision | Models used |
|---|---|
| BF16 | Qwen/Qwen3-32B |
| FP8 | Qwen/Qwen3-32B-FP8 |
| NVFP4 | RedHatAI/Qwen3-32B-NVFP4 |
Commands
All commands below assume a single precision variant is active at a time. Pick one of the three MODEL / DTYPE / SUFFIX triplets and re-run the full sweep before moving to the next.
# Pick one of the three precision variants.
MODEL="Qwen/Qwen3-32B"; DTYPE="bfloat16"; SUFFIX="bf16"
# MODEL="Qwen/Qwen3-32B-FP8"; DTYPE="auto"; SUFFIX="fp8"
# MODEL="RedHatAI/Qwen3-32B-NVFP4"; DTYPE="auto"; SUFFIX="nvfp4"vLLM Serve
vllm serve "$MODEL" \
--dtype "$DTYPE" \
--served-model-name "$MODEL" \
--host 0.0.0.0 \
--port 8000ShareGPT Client
This is the vllm bench serve client command used for ShareGPT latency and throughput testing. The dataset is the public ShareGPT_V3_unfiltered_cleaned_split.json — a synthetic conversation workload, not Jarvislabs production traffic — and is downloaded once into the working directory before running the sweep.
# Run for CONCURRENCY in 8, 16, 32, 64, 128.
# For the unbounded "no-limit" stress run, drop the --max-concurrency flag entirely.
CONCURRENCY=128
vllm bench serve \
--backend openai \
--model "$MODEL" \
--tokenizer "$MODEL" \
--base-url http://127.0.0.1:8000 \
--endpoint /v1/completions \
--seed 42 \
--dataset-name sharegpt \
--dataset-path ShareGPT_V3_unfiltered_cleaned_split.json \
--num-prompts 1000 \
--request-rate inf \
--max-concurrency "$CONCURRENCY" \
--save-result \
--save-detailed \
--result-dir "$(pwd)/results/qwen3_32b_${SUFFIX}" \
--result-filename "sharegpt_1000_concurrency_${CONCURRENCY}.json"GPQA Diamond
Use the same served model name as the active vllm serve command.
lm_eval \
--model local-completions \
--model_args model="${MODEL}",base_url=http://127.0.0.1:8000/v1/completions,max_retries=3,tokenized_requests=False,max_length=4096 \
--tasks gpqa_diamond_zeroshot \
--num_fewshot 0 \
--batch_size 1 \
--output_path "results/lmeval/qwen3_32b_${SUFFIX}_gpqa"ARC Challenge
lm_eval \
--model local-completions \
--model_args model="${MODEL}",base_url=http://127.0.0.1:8000/v1/completions,max_retries=3,tokenized_requests=False,max_length=4096 \
--tasks arc_challenge \
--num_fewshot 0 \
--batch_size 1 \
--output_path "results/lmeval/qwen3_32b_${SUFFIX}_arc_challenge"ShareGPT
BF16
| Concurrency | Throughput/sec (tok/s) | Mean TTFT (ms) | Mean TPOT (ms) | Mean ITL (ms) |
|---|---|---|---|---|
| 8 | 165.51 | 169.81 | 47.35 | 47.33 |
| 16 | 310.86 | 185.35 | 49.82 | 49.68 |
| 32 | 546.59 | 232.40 | 54.85 | 54.70 |
| 64 | 869.45 | 338.51 | 65.57 | 64.54 |
| 128 | 1155.86 | 704.38 | 93.92 | 87.50 |
| No limit | 1158.87 | 38937.28 | 253.29 | 156.53 |
FP8
| Concurrency | Throughput/sec (tok/s) | Mean TTFT (ms) | Mean TPOT (ms) | Mean ITL (ms) |
|---|---|---|---|---|
| 8 | 287.17 | 107.55 | 27.26 | 27.24 |
| 16 | 531.91 | 121.07 | 29.04 | 28.96 |
| 32 | 908.25 | 152.00 | 33.07 | 32.93 |
| 64 | 1339.78 | 248.61 | 43.65 | 42.33 |
| 128 | 1557.58 | 480.69 | 68.81 | 63.59 |
| No limit | 1916.05 | 14107.08 | 379.66 | 154.97 |
NVFP4
| Concurrency | Throughput/sec (tok/s) | Mean TTFT (ms) | Mean TPOT (ms) | Mean ITL (ms) |
|---|---|---|---|---|
| 8 | 317.22 | 79.20 | 24.72 | 24.74 |
| 16 | 614.83 | 85.66 | 25.14 | 25.13 |
| 32 | 1132.18 | 102.01 | 26.33 | 26.30 |
| 64 | 1823.97 | 148.13 | 31.02 | 30.62 |
| 128 | 2050.16 | 287.86 | 46.73 | 44.10 |
| No limit | 2898.80 | 8104.00 | 219.66 | 93.02 |
Insights
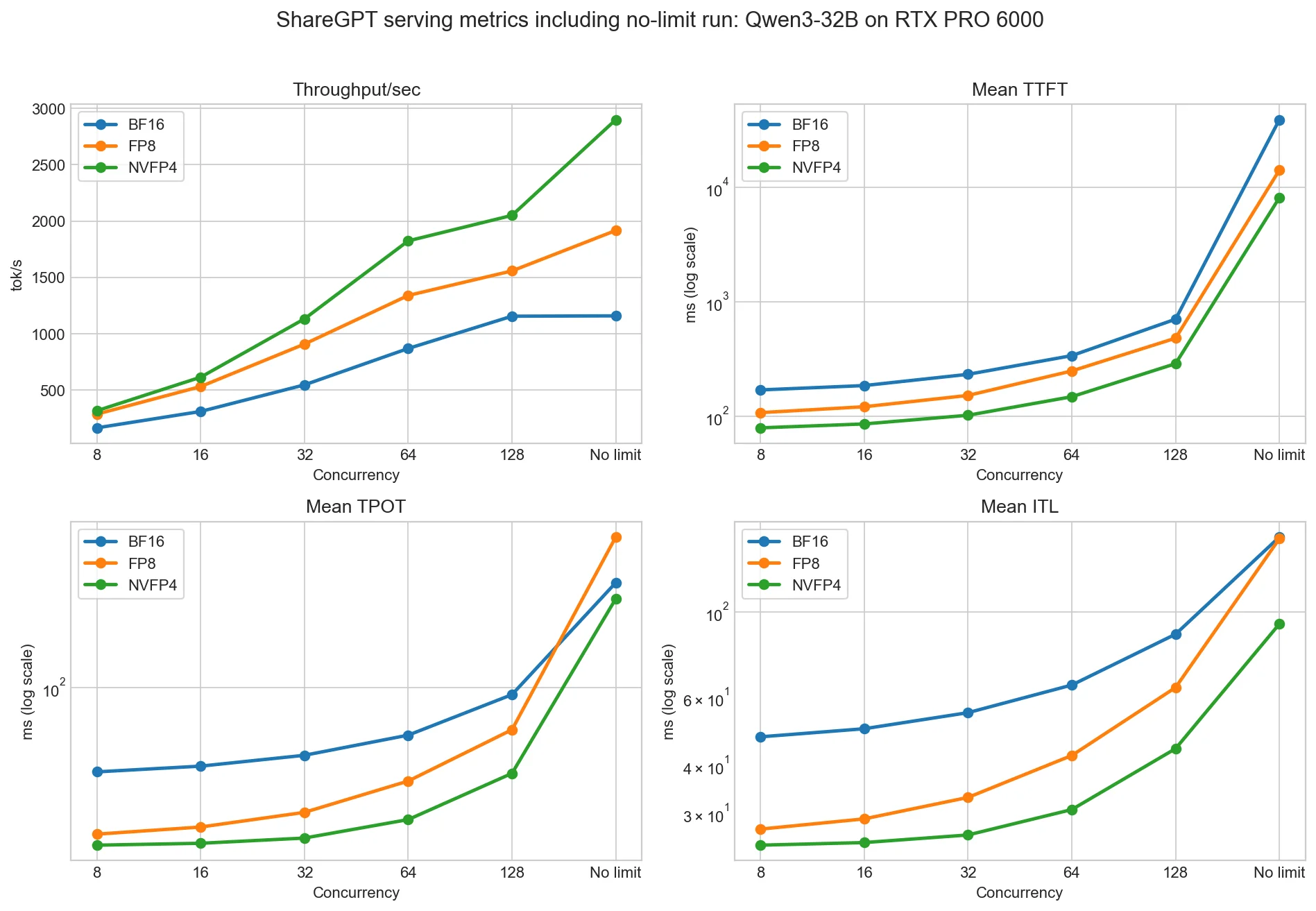
NVFP4 performed best in this sweep. Across bounded concurrency 8–64, NVFP4 ran at roughly 1.9–2.1x BF16 throughput. At concurrency 128 the gap tightens to 1.77x (2050.16 tok/s vs 1155.86 tok/s for BF16, with FP8 at 1557.58 tok/s); we didn't dig into the cause of the smaller gain at this single concurrency point in this run.
The latency gap also favors lower precision. At concurrency 64, mean TTFT is 148.13 ms for NVFP4, 248.61 ms for FP8, and 338.51 ms for BF16. So NVFP4 improves both mean throughput and mean first-token responsiveness in this setup.
BF16 barely improves throughput from concurrency 128 to no-limit (+0.26%), while mean TTFT jumps from 704.38 ms to 38937.28 ms. The "no-limit" column is best read as an unbounded stress test rather than a serving operating point — it sends all 1000 prompts at time zero, which is not how production traffic arrives.
GPQA Diamond
BF16
| Model | Metric | Value | Stderr |
|---|---|---|---|
Qwen/Qwen3-32B | acc | 0.3939 | 0.0348 |
| acc_norm | 0.3939 | 0.0348 |
FP8
| Model | Metric | Value | Stderr |
|---|---|---|---|
Qwen/Qwen3-32B-FP8 | acc | 0.3889 | 0.0347 |
| acc_norm | 0.3889 | 0.0347 |
NVFP4
| Model | Metric | Value | Stderr |
|---|---|---|---|
RedHatAI/Qwen3-32B-NVFP4 | acc | 0.3939 | 0.0348 |
| acc_norm | 0.3939 | 0.0348 |
GPQA Graph
Insights
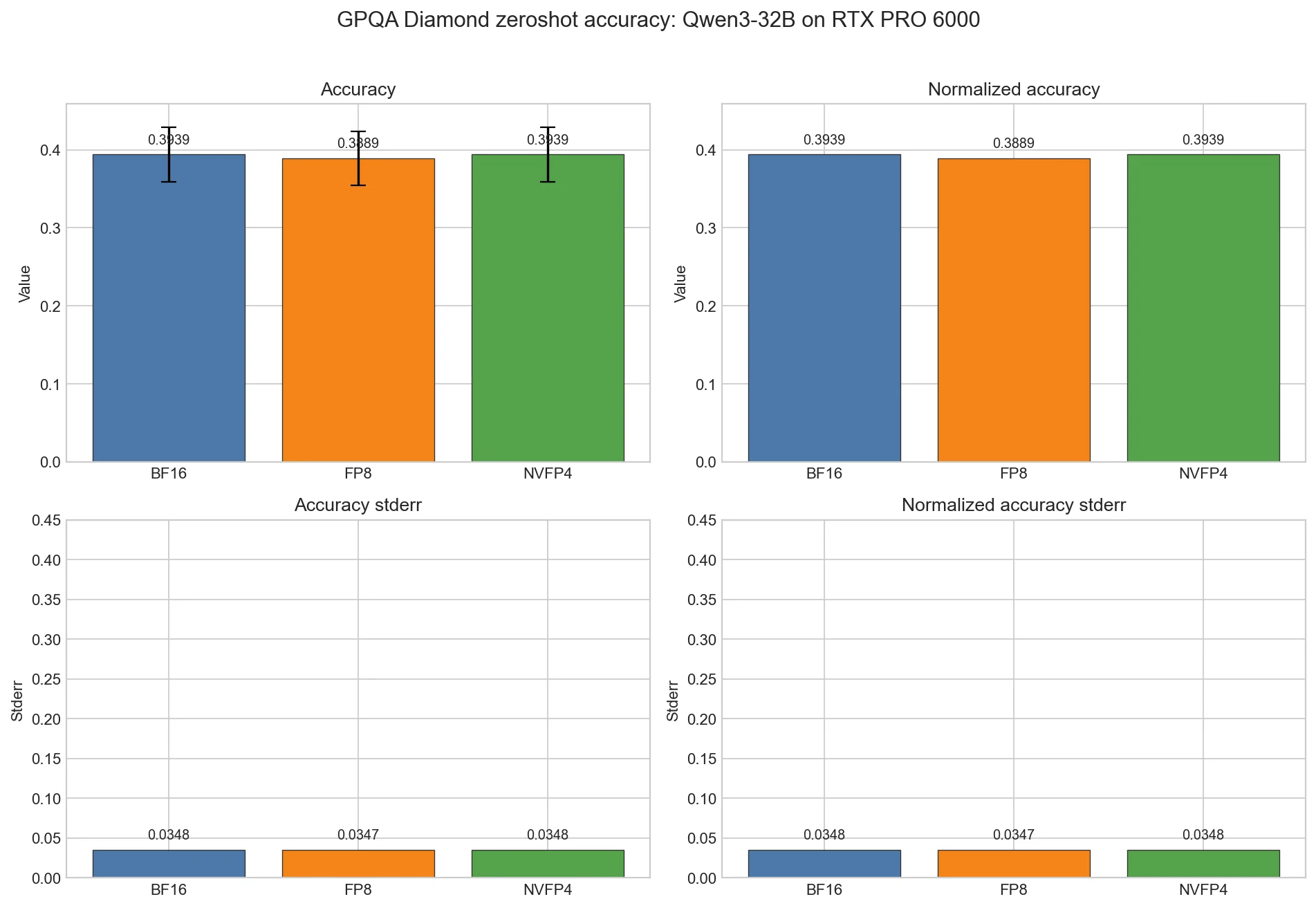
BF16 and NVFP4 are tied on GPQA Diamond with 0.3939 acc and 0.3939 acc_norm. FP8 is slightly lower at 0.3889 on both metrics.
The difference between FP8 and the other two formats is only 0.0050, which is smaller than the reported stderr of about 0.0347 to 0.0348. From this run alone, GPQA quality looks effectively unchanged across the three precisions.
ARC Challenge Results
BF16
| Model | Metric | Value | Stderr |
|---|---|---|---|
Qwen/Qwen3-32B | acc | 0.5751 | 0.0144 |
| acc_norm | 0.6118 | 0.0142 |
FP8
| Model | Metric | Value | Stderr |
|---|---|---|---|
Qwen/Qwen3-32B-FP8 | acc | 0.5836 | 0.0144 |
| acc_norm | 0.5998 | 0.0143 |
NVFP4
| Model | Metric | Value | Stderr |
|---|---|---|---|
RedHatAI/Qwen3-32B-NVFP4 | acc | 0.5802 | 0.0144 |
| acc_norm | 0.5990 | 0.0143 |
ARC Challenge Graph
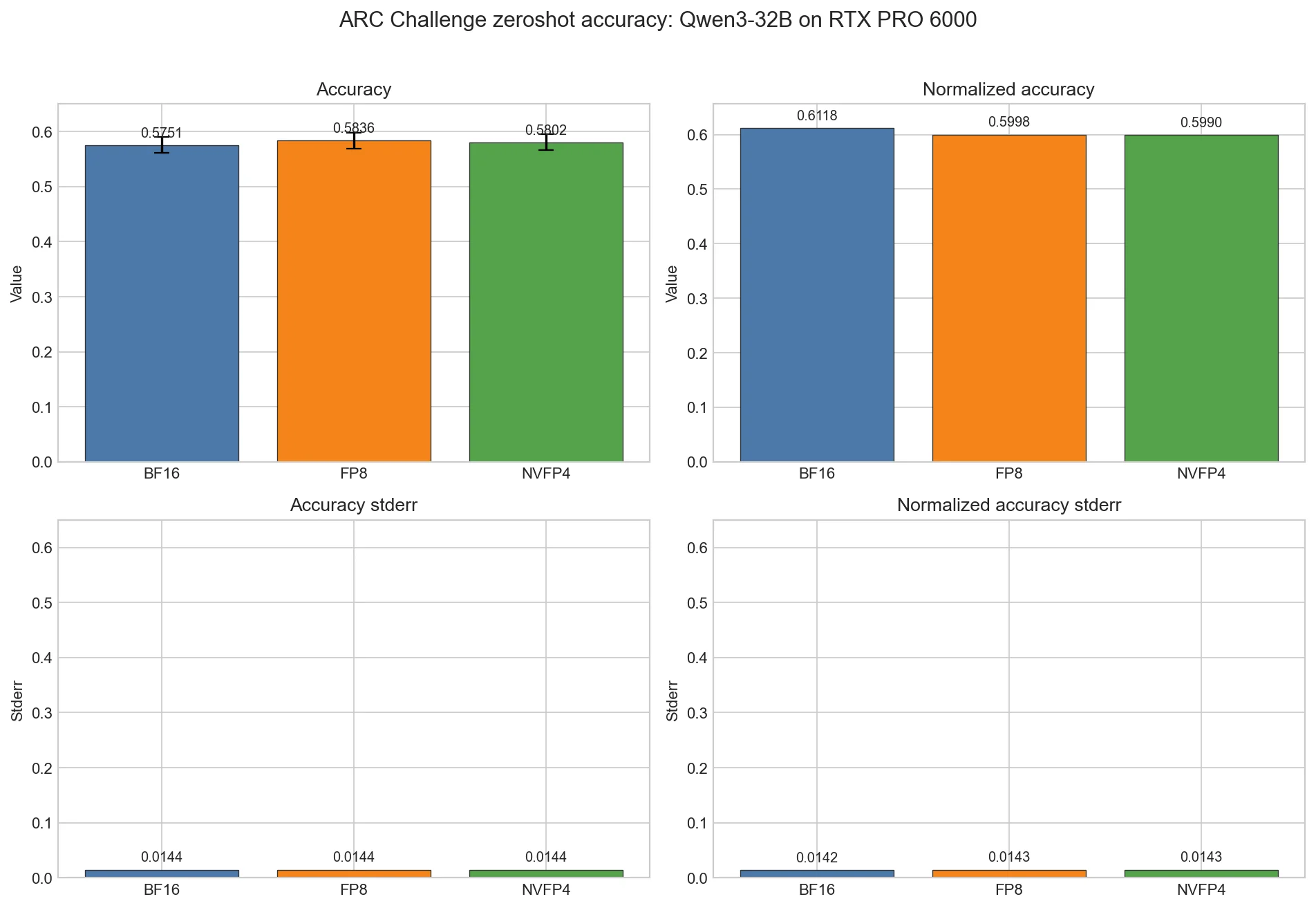
Insights
FP8 has the highest raw ARC Challenge acc at 0.5836, followed by NVFP4 at 0.5802 and BF16 at 0.5751.
BF16 has the highest acc_norm at 0.6118. FP8 and NVFP4 are close behind at 0.5998 and 0.5990. The normalized score moves differently from raw accuracy, so ARC does not show a single precision winning both metrics.
The ARC differences are small relative to stderr. The serving gains from FP8 and NVFP4 are much larger than the observed ARC accuracy movement.
Conclusion
From these runs on RTX PRO 6000, lower precision improved ShareGPT throughput and mean first-token latency for Qwen3-32B across the tested bounded concurrency points. NVFP4 delivered roughly 1.9–2.1x BF16 throughput across bounded concurrency 8–64, and 1.77x at concurrency 128, with FP8 landing in between.
The strong 4-bit showing here is the combination of NVFP4 specifically, a checkpoint prepared for it (RedHatAI/Qwen3-32B-NVFP4), and a serving stack that handles it well. Other 4-bit quantization approaches may not give the same speed-vs-accuracy balance.
On accuracy, the checks did not show a statistically meaningful regression from FP8 or NVFP4 versus BF16 in this single-run evaluation. GPQA Diamond is effectively tied across the three precisions within stderr; ARC Challenge shows small metric-specific shifts (FP8 leads on raw accuracy, BF16 leads on acc_norm) that are within ~1 stderr. That is not the same as proving NVFP4 is lossless — it means we did not observe measurable degradation on these two English multiple-choice benchmarks under this harness configuration.
A specific caveat: the RedHatAI/Qwen3-32B-NVFP4 model card explicitly scopes intended use to English, and both GPQA Diamond and ARC Challenge are English benchmarks, so these results should not be read as multilingual quality validation. Workloads that rely on non-English prompts, very long contexts, or Qwen3's thinking mode need their own validation pass.
For practical serving in this setup, NVFP4 around concurrency 64 looked like the strongest latency-throughput point. It delivers high throughput without the severe first-token latency seen in the unbounded no-limit run.
Bottom line: on Blackwell hardware, NVFP4 with a properly prepared checkpoint is a strong default for Qwen3-32B serving. Before replacing BF16 in production, validate NVFP4 on your own prompts, languages, and quality gates — the precision-vs-quality story can shift with the workload, even when the benchmark numbers look clean.
Get Started
Build & Deploy Your AI in Minutes
Cloud GPU infrastructure designed specifically for AI development. Start training and deploying models today.
View Pricing